
Como instalar um Cluster do Apache Spark no Docker Desktop utilizando Compose
- Rodrigo Saito
- 13 de out. de 2025
- 5 min de leitura

Atualizado: 13 de out. de 2025
Fala pessoal, tudo bem
Voce sabe o que é o Apache Spark?
O Apache Spark é um mecanismo analítico unificado para processamento de dados em larga escala. Ele fornece APIs de alto nível em Java, Scala, Python e R, além de um mecanismo otimizado que suporta gráficos de execução gerais. Ele também suporta um amplo conjunto de ferramentas de alto nível, incluindo Spark SQL para SQL e processamento de dados estruturados, API Pandas no Spark para cargas de trabalho Pandas, MLlib para aprendizado de máquina, GraphX para processamento de gráficos e Structured Streaming para computação incremental e processamento de fluxo.
No docker, o Apache Spark terá a seguinte infra-estrutura:

Para montarmos um cenário próximo a esse, iremos usar o arquivo compose;
Crie uma pasta (preferencialmente dentro da onde o seu docker já abre o terminal) e edite o docker-compose.yml com o conteúdo abaixo e salve o arquivo
services:
spark-master:
image: apache/spark:latest
container_name: spark-master
hostname: spark-master
command: bash -c "/opt/spark/bin/spark-class org.apache.spark.deploy.master.Master"
ports:
- "7077:7077" # Porta para comunicação com workers
- "8080:8080" # UI do Spark Master
environment:
- SPARK_HOME=/opt/spark
networks:
- spark-net
spark-worker-1:
image: apache/spark:latest
container_name: spark-worker-1
hostname: spark-worker-1
command: bash -c "/opt/spark/bin/spark-class org.apache.spark.deploy.worker.Worker spark://spark-master:7077"
depends_on:
- spark-master
ports:
- "8081:8081" # UI do Spark Worker 1
environment:
- SPARK_HOME=/opt/spark
networks:
- spark-net
spark-worker-2:
image: apache/spark:latest
container_name: spark-worker-2
hostname: spark-worker-2
command: bash -c "/opt/spark/bin/spark-class org.apache.spark.deploy.worker.Worker spark://spark-master:7077"
depends_on:
- spark-master
ports:
- "8082:8081" # Worker 2 exposto na porta 8082
environment:
- SPARK_HOME=/opt/spark
networks:
- spark-net
#Parte 2 - Adicionando o Jupyter + Spark
jupyter:
image: jupyter/all-spark-notebook:latest
container_name: jupyter
hostname: jupyter
ports:
- "8888:8888"
environment:
- SPARK_HOME=/usr/local/spark
volumes:
- ./notebooks:/home/jovyan/work
- ./notebooks:/conf/spark-defaults.conf:/usr/local/spark/conf/spark-defaults.conf
depends_on:
- spark-master
networks:
- spark-net
networks:
spark-net:
driver: bridge
Observação: O arquivo desse docker-compose.yml pode ser encontrado em:
Dentro da pasta que foi salvo o arquivo, digite:
docker-compose up -d
Serão baixadas as imagens do Apache Spark. Os arquivos são grandes, a qual pode demorar um pouco dependendo da conexão de sua internet.
E os containers também subirão:

Clique em Containers e veja que está sendo executado todo o cluster configurado:

Acesse via browser, o localhost:8080 e veja que o serviço está sendo executado.

Vamos ter que configurar o arquivo
No VS Code, instale as extensões Dev Containers e Containers Tools, ambos da Microsoft:


Clique em cima da extensão instalada em Dev-Containers, selecione o spark jupyter.

Clique em Explorer do VS Code e depois em "Open Folder"
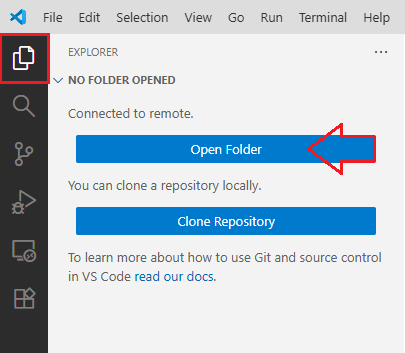
Clique na barra de comandos do VS Code, deixe a pasta como está e clique em OK
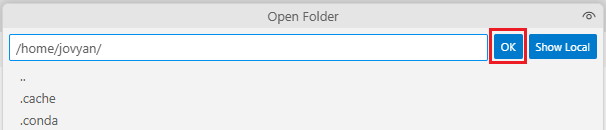
Perceba que agora no Explorer, voce está enxergando a estrutura de pastas que está dentro do container.
Dentro da pasta notebooks, crie uma pasta chamada conf e um novo arquivo chamado spark-default.conf

O arquivo spark-default.conf pode ser baixado em:
Coloque esse conteúdo no arquivo:
spark.master spark://spark-master:7077
spark.submit.deployMode client
spark.driver.host jupyter
spark.driver.bindAddress 0.0.0.0
spark.ui.enabled trueSerá necessário fazer a releitura do arquivo novamente, para a crediação do cluster:
Digite o comando no prompt do docker
docker-compose restart
Teste o container com os seguintes passos:
Ainda no prompt do docker, será necessário entrar no bash do container jupyter. Digite o seguinte comando:
docker exec -it jupyter bash
Entre na pasta work dentr do container jupyter:
cd work
Precisamos do endereco com o token para acessar via browser do localhost. Digite o comando:
jupyter server list
Copie o endereco http e cole no endereço do browser. Ele irá dar erro:

Substitua no endereço somente o jupyter por localhost e entre dentro da pasta work. Clique em Python 3 (ipyKernel)

Dê o nome do arquivo de SimpleTest

O arquivo SimpleTest pode ser baixado em: https://github.com/datalibtec/spark/blob/main/SPK%20001%20-%20SimpleTest.ipynb
Digite o código que está descrito e salve o arquivo
from pyspark.sql import SparkSession
spark = SparkSession.builder.getOrCreate()
spark.range(1000).show()Execute o arquivo e o resultado irá aparecer:

Esse é o primeiro arquivo e quer dizer que o pyspark está utilizando o Spark.
Feche esse arquivo.
Faça upload de uma arquivo vendas.csv, que pode ser encontrado em nosso github, em:

O arquivo CSV tem o seguinte conteúdo:
produto,quantidade,preco_unitario
Camiseta,10,29.90
Calça,5,79.90
Tênis,2,199.90
Camiseta,7,29.90
Calça,3,79.90
Tênis,1,199.90Faça download do nosso arquivo vendas.ipynb
# Importar bibliotecas do PySpark
from pyspark.sql import SparkSession
from pyspark.sql.functions import col, sum
# Criar uma sessão Spark conectada ao cluster
# SparkSession: ponto de entrada para usar Spark com Python.
spark = SparkSession.builder.getOrCreate()
# Carregar o arquivo CSV como DataFrame
# DataFrame: estrutura tabular de dados, como uma planilha.
df = spark.read.csv("vendas.csv", header=True, inferSchema=True)
# Mostrar os dados carregados
df.show()Será mostrada a seguinte tabela:

(continuação do arquivo)
# Calcular total vendido por linha
# withColumn: cria nova coluna com base em cálculo.
df_com_total = df.withColumn("total_vendido", col("quantidade") * col("preco_unitario"))
# Agrupar por produto e somar
# groupBy + agg: agrupa dados e aplica funções como soma.
# show(): exibe os dados no terminal.
df_agrupado = df_com_total.groupBy("produto").agg(sum("total_vendido").alias("total_por_produto"))
df_agrupado.show()Será mostrado o resultado:
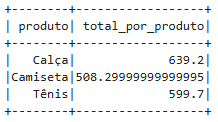
(continuação do arquivo)
# Filtrar produtos com total vendido acima de R$ 600
df_filtrado = df_agrupado.filter(col("total_por_produto") > 600)
df_filtrado.show()
Será mostrado resultado:

(continuação do arquivo)
# Salvar resultados filtrados em CSV
df_filtrado.write.csv("resultados_filtrados.csv", header=True, mode="overwrite")
#Importacao da biblioteca ploty
import plotly.express as px
O erro irá acontecer:
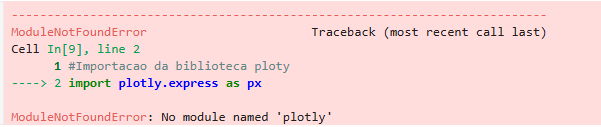
(continuação do arquivo)
#Para instalar com suporte ao Plotly Express:
!pip install plotly[express]Será feira a instalação da biblioteca:
(continuação do arquivo)
#Importacao da biblioteca ploty
import plotly.express as px
# Converter para Pandas para visualização
df_pandas = df_filtrado.toPandas()
# Criar gráfico de barras
fig = px.bar(df_pandas, x="produto", y="total_por_produto", title="Total de Vendas por Produto")
fig.show()
Na execução desse comando, deveria-se ter os gráficos plotados:
(continuação do arquivo)
!jupyter labextension install jupyterlab-plotlySerá instalado a biblioteca:

(continuação do arquivo)
!pip install -U plotly notebookSerá instaldo a biblioteca:

(continuação do arquivo)
#testando a instalacao do plotyly
import plotly.express as px
fig = px.bar(x=["A", "B", "C"], y=[10, 20, 30])
fig.show()Veja que nenhuma figura foi apresentada.
Depois de ter instalada, é necessário reiniciar o serviço dos containers. No prompt do Docker destop, digite o seguinte comando:
exitServirá para que voce volte ao prompt do power shell:

Digite o comando:
docker-compose restart
Vai ser necessário entrar novamente no prompt de interacao para pegar o endereco tokenizado:
docker exec -it jupyter bashDentro do container, digite:
jupyter server listCopie o endereco para o browser e substitua parte do endereco jupyter para localhost:
Abra novamente o arquivo vendas.ipynb e vá ao menu Kernel / Restart Kernel and Clear Outputs of All Cells:

Clique em Restart:

Vá ao menu:

Clique novamente em restart:

Role a tela para baixo e veja agora que aparecem os gráficos que o comando executa:

Agora que temos a base da infra estruturada pronta, nos proximos blogs ou vídeos, teremos como fazer a utilização do Spark.
Por enquanto obrigado e até +!
Referências:
Apache Spark, dispon[ivel em: <https://hub.docker.com/_/spark>, acessando em 04 de out. de 25.
Data Engeniring Works, disponível em: <https://karlchris.github.io/data-engineering/projects/spark-docker/>, acessado em 04 de out. de 25.
Stack Overflow, Running Kafka and Spark with docker-compose, disponível em <https://stackoverflow.com/questions/76238105/running-kafka-and-spark-with-docker-compose>, acessado em 05 de out. de 25.

Comentários